 |
| By Cosmocatalano (Own work) [CC0], via Wikimedia Commons |
6/25/2015
How Do We Protect Quality?
6/20/2015
New Look
I've applied a new visual style to the blog, and came up with a logo! I think it's better than before, but let me know what you think.
6/18/2015
What's The Difference Between A Boss And a Leader?
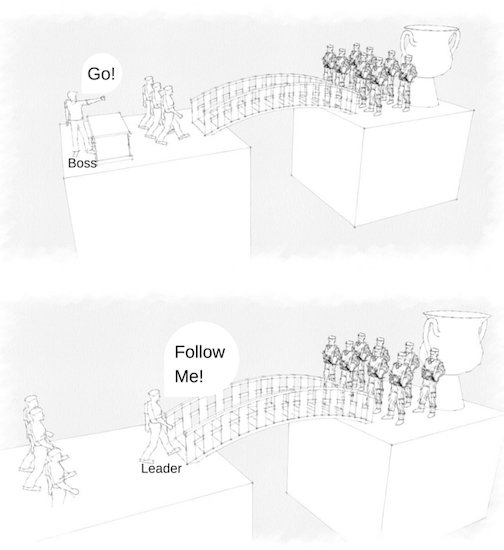
In order to capture the essence of how I mentally differentiate between bosses and leaders, I decided to get a little help from Trimble SketchUp and Canva to craft a visual metaphor of how I see bosses and leaders working differently. By the end of this post you should have a decent idea of the kind of approach you want to take in your career long term, but also the kind of approach your manager/supervisor/director/president takes within the organization as well.
As a caveat before I begin talking about the two ways people create direction in an organization, I realize some people are happy either being the figures the boss sends across the bridge, or being the ones following the leader across the bridge. I have observed over time that most people seem happier and more productive when the concept presented in the second graphic matches their job, but on occasion the concept in the first graphic can work - if you have the right kind of boss pointing the way. Usually for the bossy one to work there's actually a leader who says "boss is right, follow me" and the boss would have been leading the way in the past, but preferred to delegate instead because more than one team now depends on said boss.
This graphic includes several visual elements to represent some of the challenges we face at work every day. Here's a breakdown of what I see each one meaning, and how a boss manages differently than a leader.
Team:
At the end of the day, the team is the group of people that get the work done. Whether they bring back the prize at the behest of their boss or decide together that the prize is worth seeking, the team ultimately ends up doing the work. Most bosses (the bad ones at least) decide that they own their team, not that they are part of their team. The team is there to go get the trophy for the boss, and if a member of the team doesn’t want to go get the trophy they usually have to find another team. For bad bosses, teams are just tools that can be broken and thrown away. Most leaders (even if they lead from within a management position) are part of the team. They work together with the teammates to decide which prize to go after. And they decide with the team if they prize chosen has become too difficult to attain. When they do bring a trophy home, it goes in the trophy case that the team shares, together. And if any one member of the team starts to get weak, the rest of the team shores up to help out.
Large Desk:
This is the place where the boss makes all the decisions about where his team goes. When the fire fight starts he will also tend to use it as a shield, because after all his team is expendable, but he is not. Also, the leader has no large desk. He assumes that the best course is to convince the army at the other end to stand down, but will also take a bullet if a fire fight starts.
Chasm/Canyon:
We face uncertainty at work every day. This uncertainty separates us from our goal (the trophy) and makes the obstacles in our way (the army) all the more daunting. A boss will say "go across the canyon and return my prize. If you fail i can just find a different team that is better anyway." A leader will say, "We all agreed that the prize on the other side of the canyon is worth going after. Let's go together across to get it and share it. I'll protect you the best I know how as we cross."
Bridge:
This represents the chosen path through uncertainty. When a boss chooses a path and it's the wrong one, he usually blames the incompetence of the team for failing his vision. When a leader suggests the path the team works together to forge it. If it turns out incorrect they work together to decide on which path to try next and forge it together.
Armed Guards:
The armed guards represent the obstacles, both known and unknown, that hinder our progress towards achieving a goal. The boss tends to ignore the risk for casualties, after all he can just send in more people until the job gets done. The leader has no desire for any casualties, because the leader would insist on being the first. Nobody on the team is expendable, and everyone works together to find the best way to deal with the armed guards. With a good leader-headed team, usually the goal is reached without bullets flying. With a boss's team, the boss might get impatient and detrimentally impact any chance the team had to handle non-hostile negotiating.
Trophy:
The prize! The boss wants this for a trophy case. The team wants it because they know it is a prize worth sharing together. The team can decide together if they fight for the wrong prize and seek another instead. The boss likely can't be as easily persuaded. After all, the boss made the choice to go after the prize. Why challenge the boss' ego by thinking they are wrong?
So, where’s the Manager?
Notice nowhere on the diagram do you see the text Manager/Supervisor/Director/President. Usually speaking, a manager can be both a boss and a leader. Even the best managers that have all of the right qualities of a leader sometimes need to put on their boss suit and tie when it comes time to make the really hard calls. If a manager does have several teams that each have their own leader, and one team struggles to bring in prizes as well as the other, sometimes the manager has to decide whether it's time to reorganize teams, or to reduce the number of employees on the weaker team in the name of operational efficiency. For a good manager, when teams don’t deliver, their first step is to find out why delivery isn’t happening. For a bad manager, usually the answer is to just lay blame and find ways to doc pay, or to outright terminate people. Don’t get me wrong - if a good manager sees someone that constantly draws down the entire team, it’s up to that manager to make the hard call and cut the apron strings.
My experience with management, both in large companies and small ones, tells me that the best managers have a well balanced blend of boss and leader in their repertoire. At times, they have to have the confidence to say “Go this way, and you’ll have to trust me right now because I know you don’t have all of the data that I do. It’s the right way to go, but unfortunately I’m not in the position to go with you.” Hopefully, most of the time they have used proven leadership so that when the time comes that they have to direct instead of lead, people trust that direction. More often than not the best managers act with the concept of leadership in mind. But they have the authority to be the boss on occasion, and hopefully that’s a good thing.
As a caveat before I begin talking about the two ways people create direction in an organization, I realize some people are happy either being the figures the boss sends across the bridge, or being the ones following the leader across the bridge. I have observed over time that most people seem happier and more productive when the concept presented in the second graphic matches their job, but on occasion the concept in the first graphic can work - if you have the right kind of boss pointing the way. Usually for the bossy one to work there's actually a leader who says "boss is right, follow me" and the boss would have been leading the way in the past, but preferred to delegate instead because more than one team now depends on said boss.
This graphic includes several visual elements to represent some of the challenges we face at work every day. Here's a breakdown of what I see each one meaning, and how a boss manages differently than a leader.
Team:
At the end of the day, the team is the group of people that get the work done. Whether they bring back the prize at the behest of their boss or decide together that the prize is worth seeking, the team ultimately ends up doing the work. Most bosses (the bad ones at least) decide that they own their team, not that they are part of their team. The team is there to go get the trophy for the boss, and if a member of the team doesn’t want to go get the trophy they usually have to find another team. For bad bosses, teams are just tools that can be broken and thrown away. Most leaders (even if they lead from within a management position) are part of the team. They work together with the teammates to decide which prize to go after. And they decide with the team if they prize chosen has become too difficult to attain. When they do bring a trophy home, it goes in the trophy case that the team shares, together. And if any one member of the team starts to get weak, the rest of the team shores up to help out.
Large Desk:
This is the place where the boss makes all the decisions about where his team goes. When the fire fight starts he will also tend to use it as a shield, because after all his team is expendable, but he is not. Also, the leader has no large desk. He assumes that the best course is to convince the army at the other end to stand down, but will also take a bullet if a fire fight starts.
Chasm/Canyon:
We face uncertainty at work every day. This uncertainty separates us from our goal (the trophy) and makes the obstacles in our way (the army) all the more daunting. A boss will say "go across the canyon and return my prize. If you fail i can just find a different team that is better anyway." A leader will say, "We all agreed that the prize on the other side of the canyon is worth going after. Let's go together across to get it and share it. I'll protect you the best I know how as we cross."
Bridge:
This represents the chosen path through uncertainty. When a boss chooses a path and it's the wrong one, he usually blames the incompetence of the team for failing his vision. When a leader suggests the path the team works together to forge it. If it turns out incorrect they work together to decide on which path to try next and forge it together.
Armed Guards:
The armed guards represent the obstacles, both known and unknown, that hinder our progress towards achieving a goal. The boss tends to ignore the risk for casualties, after all he can just send in more people until the job gets done. The leader has no desire for any casualties, because the leader would insist on being the first. Nobody on the team is expendable, and everyone works together to find the best way to deal with the armed guards. With a good leader-headed team, usually the goal is reached without bullets flying. With a boss's team, the boss might get impatient and detrimentally impact any chance the team had to handle non-hostile negotiating.
Trophy:
The prize! The boss wants this for a trophy case. The team wants it because they know it is a prize worth sharing together. The team can decide together if they fight for the wrong prize and seek another instead. The boss likely can't be as easily persuaded. After all, the boss made the choice to go after the prize. Why challenge the boss' ego by thinking they are wrong?
So, where’s the Manager?
Notice nowhere on the diagram do you see the text Manager/Supervisor/Director/President. Usually speaking, a manager can be both a boss and a leader. Even the best managers that have all of the right qualities of a leader sometimes need to put on their boss suit and tie when it comes time to make the really hard calls. If a manager does have several teams that each have their own leader, and one team struggles to bring in prizes as well as the other, sometimes the manager has to decide whether it's time to reorganize teams, or to reduce the number of employees on the weaker team in the name of operational efficiency. For a good manager, when teams don’t deliver, their first step is to find out why delivery isn’t happening. For a bad manager, usually the answer is to just lay blame and find ways to doc pay, or to outright terminate people. Don’t get me wrong - if a good manager sees someone that constantly draws down the entire team, it’s up to that manager to make the hard call and cut the apron strings.
My experience with management, both in large companies and small ones, tells me that the best managers have a well balanced blend of boss and leader in their repertoire. At times, they have to have the confidence to say “Go this way, and you’ll have to trust me right now because I know you don’t have all of the data that I do. It’s the right way to go, but unfortunately I’m not in the position to go with you.” Hopefully, most of the time they have used proven leadership so that when the time comes that they have to direct instead of lead, people trust that direction. More often than not the best managers act with the concept of leadership in mind. But they have the authority to be the boss on occasion, and hopefully that’s a good thing.
6/11/2015
How do I Deal With Major Mistakes?

My biggest mistake in this situation was in trusting a deployment pipeline to give us the right answer about the deployment of the application we were working on. A critical bug was discovered in production, and we had assumed we fixed all of the edge cases that caused the bug and deployed confidently on this assumption. It turns out there were more edge cases. Lots of them. And our deployment pipeline had no knowledge of them, so it happened again. After we confidently said it was fixed. Ouch.
So, several things had to happen after my major mishap. First, and foremost, though - I took ownership of it. Several people were either directly or indirectly involved in the writing of this code and the decision to deploy it, but at the end of the day I had to have the ultimate final say-so that we'd gotten the solution good enough to face our (internal) customers, and I signed off on the solution. So, I found my boss and told him exactly what happened, as honestly as I could, about how this code could get into production in a still broken state. In order to maintain respect within my team and organization, taking responsibility for the error was the best way to show that my professional integrity, though sullied, was far from failing completely.
Next, we worked as efficiently as we possibly could to get the issue fixed. Thankfully it was a job that ran once a month, so between runs we had a little bit of time to clean the egg off of my face.
After that, we went through the process that lead to the broken deployment. We laid out all of the decision points that could have lead to the failure, and determined where I could make some changes in my own methods for reviewing software to help prevent errors like this in the future. What this basically amounted to was learning where the deployment pipeline wasn't reliable, and finding out how to deal with this in any further deployment - with a manual checklist.
At the end of it all, once I'd cleaned the egg off of my face (with my team's help) and grudgingly accepted the major ding in my quarterly goals review, the most important thing of all was to review the bad time as a learning experience.
Recently, I was asked if I was going to fire an employee who made a mistake that cost the company $600,000. No, I replied, I just spent $600,000 training him. Why would I want somebody to hire his experience? - Thomas John Watson Sr. - First CEO at IBM1
It's possible to learn from success - at least as far as knowing the things that you can repeat to keep being successful. But the kind of learning that you gain from a failure is akin to the kind of learning you do when you put your hand on the hot stove for the very first time. It stays seared into long-term memory, and helps to propel greater things. We all need to stand on the shoulders of our past mistakes, knowing that we're strong enough to make different mistakes in the future. At the end of the day, if you work somewhere that you respect, and that has respect for your talent - you'll get the opportunity to prove you can be trusted, and you'll also get the opportunity to prove that sometimes - mistakes are just really expensive training exercises.
- If anyone has a source where this quote was captured originally I'm happy to cite it here. This is just a citation of someone else that re-used it. http://www.inc.com/murray-newlands/30-quotes-to-remember-when-recruiting-for-your-startup.html
6/04/2015
Should Code Have "Come Back to this Later" Comments?
We did this today.
I'm not particularly proud of writing code of any kind that has these kinds of statements in it. I tend to repeat the mantra "If we don't have time to do it right, when will we have time to do it over?" in my head somewhat repeatedly. I've even known to say it out loud on occasion. And yet, here I am staring at a bash comment with the big green word HACK in it. I plan on doing the walk of shame later, for now I'm going to explain why I feel like there's a few of important rules to assume when you're writing code at work.
# HACK: Fix this later, this is awful
ssh $USERNAME@$TARGET '
for file in $(grep -rl some-string-we-need-to-replace /some/directory/to/do/work/in)
do sudo sed -e "s/some-string-we-need-to-replace/the-string-to-replace-it-with/g" -i $file
done'
I'm not particularly proud of writing code of any kind that has these kinds of statements in it. I tend to repeat the mantra "If we don't have time to do it right, when will we have time to do it over?" in my head somewhat repeatedly. I've even known to say it out loud on occasion. And yet, here I am staring at a bash comment with the big green word HACK in it. I plan on doing the walk of shame later, for now I'm going to explain why I feel like there's a few of important rules to assume when you're writing code at work.
- You're never going to come back to code that you write "I need to come back to this later" in the comments. While this may not always hold true, in general if the software "works" as is, you're going to have a very difficult time convincing your boss/customer/whoever that you need to go back and fix it if they don't see anything broken to begin with.
- Any time you do write "TODO", "FIXME", "HACK", or your favorite word that is supposed to make you fix it later, you need to make your boss/customer/whoever understand that you do need to take the time to go back and fix it later. This is usually very difficult.
- Sometimes real deadlines in the release environment make it so that we have to cut corners and just get something deployed. We don't have time to do it right, right now, because we have a customer waiting for it. Just be ready to do it over when something unexpected happens because of your TODO, and be ready to get a good bit of egg on your face if it does happen in the wild. Be VERY selective about how and when you use TODO statements in your code. Production code with TODO in it doesn't seem like it belongs as production code (to me).
- There's an exception where you're doing something like "TODO: Need to make sure to remember that when we're implementing feature AWESOME-1234 that this is the right place to put controller/domain/dao/magic logic." TODO reminders about future new features are OK, most of the time.
We all have to write code we're immediately sickened by when our fingers type it. Hopefully we all find ourselves in roles where we don't have to do it all that frequently. But, it does happen (see: http://www.commitstrip.com/en/2015/05/29/always-stuck-somewhere-in-my-head/) - so we need to be careful about how we exercise our powers of evil getting things done. Otherwise we may end up writing "TODO: Find new customers because the old ones don't trust us any more" - and nobody wants to have to write that.
Subscribe to:
Posts (Atom)